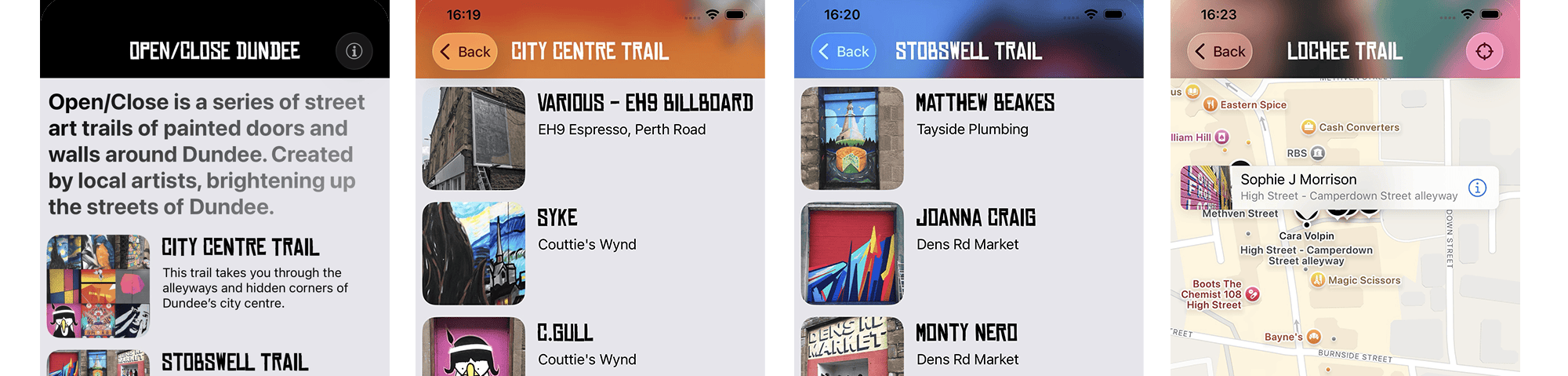
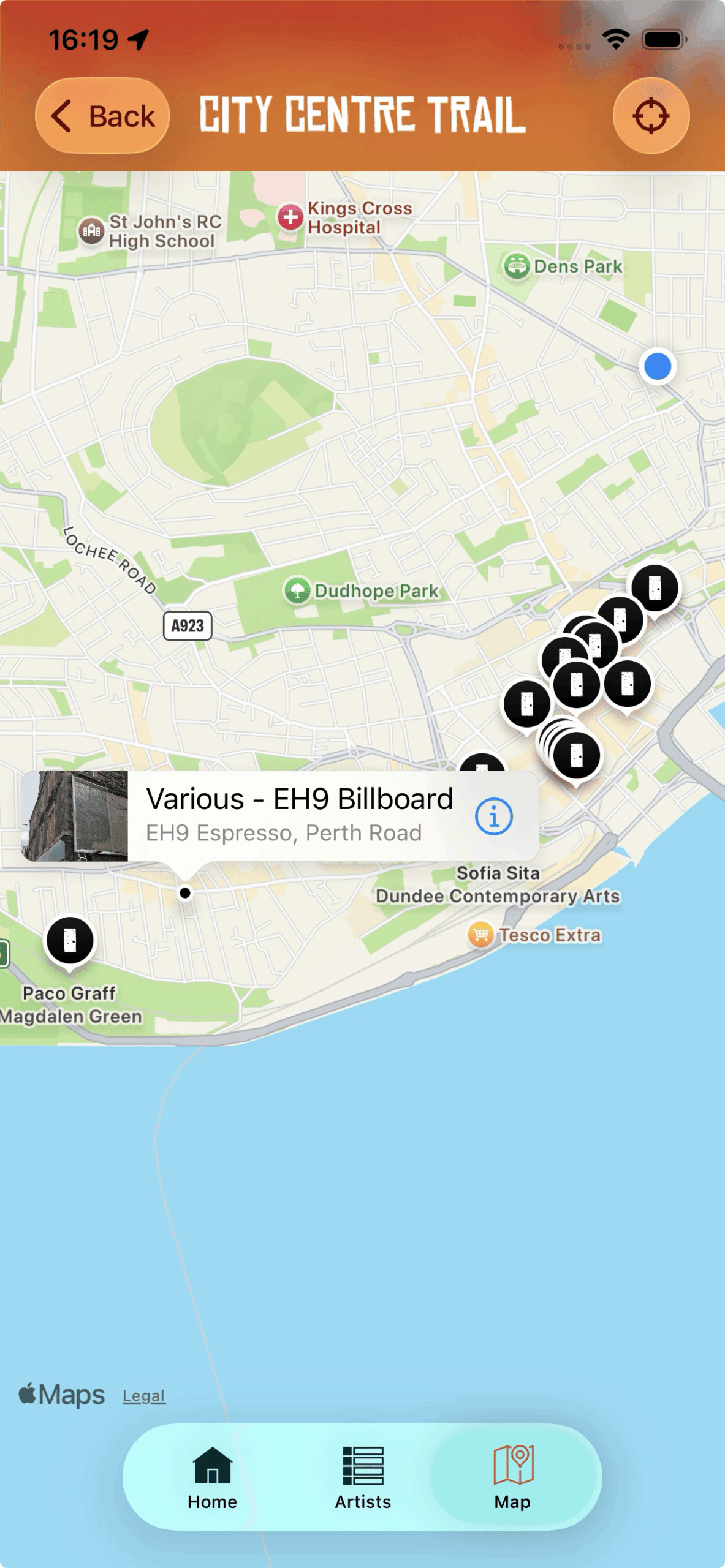
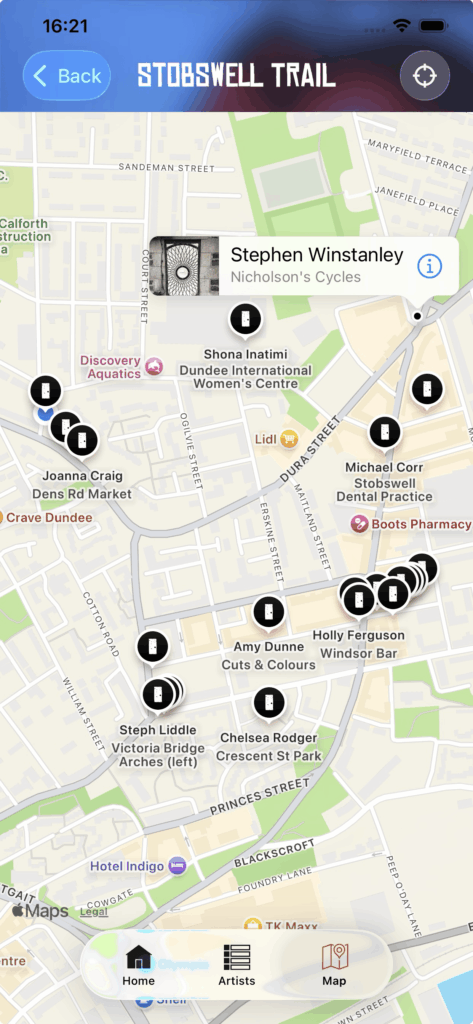
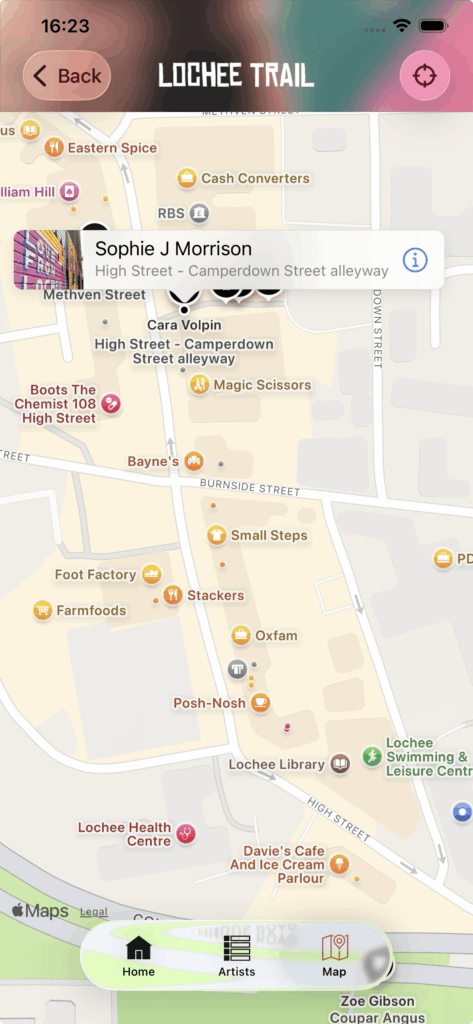
Spotify started the yearly “wrapped” trend back in 2016 giving you a roundup / overview of your music listening habits over the year, but now many other services are doing a “wrapped” style roundup with Apple Music, YouTube and even Lidl supermarket did one for your 2025 annual shopping habits in their Lidl plus app!
ChatGPT also added a specific “Your Year with ChatGPT” option where you could see your activity over the year which highlights the number of conversations, messages, topics explored etc (tip: type “Your Year with ChatGPT” into a prompt and it will generate this for you).
Whilst it’s interesting to see the various activity within ChatGPT one thing they don’t highlight are the resources that were used in the process, e.g. things like energy, water, CO2 emissions.
The resource usage of AI / AI data centres is a huge topic and it is difficult to get clear details of exactly how much energy is being consumed when you enter a prompt into ChatGPT, there have definitely been some extremely exaggerated figures of water usage thrown around but equally there is a lack of clear transparency from companies like OpenAI, Anthropic, Microsoft etc.
Despite this challenge I thought it would be good to have an alternative ChatGPT “wrapped” tool and at least attempt to help us see how our usage of ChatGPT measures up. The figures I’ve used are based on general data about AI usage / data centres so not strictly what ChatGPT uses so you could swap out “ChatGPT and insert the name of whichever AI company you might be using.
(Note I’ve included some specific info below the tool in “How are these calculated?“, if you disagree or have any better statistics then please do leave a comment, I’m trying to base this on real data which as I’ve said is a little hard to ascertain exact numbers).
So, finally, I present my version of “ChatGPT Wrapped”:
Your ChatGPT Wrapped
How are these calculated?
Estimates in this tool are based on publicly available research into large language model inference, data centre electricity use, cooling infrastructure, and agricultural water footprints.
Independent investigations have shown that the environmental footprint of an individual AI query can vary significantly depending on the model used, data centre location, cooling method, and electricity grid. As a result, no single “per-query” value can be considered definitive.
To make these comparisons concrete, this tool uses the following per-query assumptions:
- Energy: ~0.0005 kWh per ChatGPT query (0.5 watt-hours)
- Water: ~0.005 litres per ChatGPT query (5 millilitres)
- CO₂: ~0.0003 kg per ChatGPT query (0.3 grams)
- MIT Technology Review – “We did the math on AI’s energy footprint”
- WIRED – “You’re Thinking About AI and Water All Wrong”
- International Energy Agency – Digitalisation and energy
- Water Footprint Network – Product water footprints
- Sam Altman - “The Gentle Singularity”
- The Verge - “Sam Altman claims an average ChatGPT query uses ‘roughly one fifteenth of a teaspoon’ of water”
- “How Hungry is AI?” – LLM inference benchmarking study
- Epoch AI – updated estimates of per-query energy use
- OECD – water use in AI systems
Values shown are mid-range averages intended for awareness and comparison, not precise accounting.
You may see much lower water-use figures quoted elsewhere, including estimates from OpenAI that focus on direct, on-site cooling water at highly optimised data centres. This tool uses broader, system-level estimates that also account for indirect water use associated with electricity generation and supporting infrastructure.
In addition, real-world AI usage varies widely. Simple text prompts typically require less compute than image generation, longer conversations, or multi-step analysis. The values shown here are intended to reflect an average across a mix of common usage patterns rather than a best-case scenario.
Why do these numbers vary?
AI systems don’t operate in a single, fixed environment. The resources required to generate a response depend on where and how that response is produced, and on the wider systems that support it. For this reason, estimates of energy, water, and emissions are best understood as ranges rather than exact values. The figures shown here are mid-range estimates intended to provide context, not precise measurement.